Un-Supervised learning is a type of machine learning that uses un-labeled data sets and produces output that is just based on perceptions. Unlike supervised learning, un-supervised learning is more complex and performs real-time analysis. The results are comparatively less accurate than supervised learning. It does not need any type of human intervention and uses algorithms that discover hidden patterns or grouping. However, you can go through the data groupings and classify them based on your understanding.
Working Principles
Suppose you have a group of uncategorized data; the un-supervised learning algorithm will process the raw input data and group it according to their similarities and differences and produce output into two groups A and B.
It can be understood from the following example:
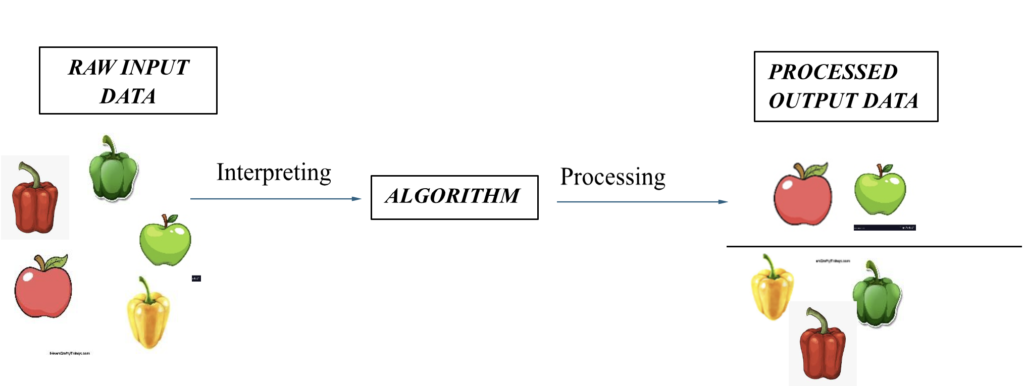
When the un-supervised algorithm is fed with uncategorised images of different types of apples and bell peppers, it interprets the data by identifying the image features on its own. It categorizes them into two groups depending on their common nature.
Mathematical Foundations
Unlike supervised learning, which has an error minimization formula, un-supervised learning does not have a universal formula for tackling unlabeled data. Hence, the mathematical approaches depend on the specific algorithm being used and its goals.
These algorithms are distance matrices, k-means clustering, probability distributions, and an optimization technique. For example, the following formula is used for the Euclidean distance matrix.
$$d(x, y) = \sqrt{(x_1 – y_1)^2 + (x_2 – y_2)^2 + \dots + (x_n – y_n)^2}$$
- \(d(x, y)\): This represents the distance between two points x and y in n-dimensional space.
- \((x_{1},x_{2}, …x_{n})\): This denotes the coordinates of the point x in n dimensions.
- \((y_{1}, y_{2}, …, y_{n})\): This denotes the coordinates of the point y in n dimensions.
Algorithm Categories
Un-Supervised learning contains three types of problem-solving strategies:
- Clustering
- Association (Data mining)
- Dimensionality reduction
- Clustering
The process in which the objects are categorized or grouped based on their similarities is called clustering. Unlike supervised learning, it does not aim at a known or targeted variable, instead, it aims to gain insights from unlabeled data sets.
In cluster analysis, similar objects are grouped into one cluster while the other objects in other clusters are different, it gives us underlying patterns of different groups.
Clustering mainly consists of further two types: partitional clustering and hierarchical clustering.
- Association Rules
An association rule or data mining is a rule-based method for finding relationships between the objects and variables present in large data sets. Marketing strategy is made more effective by the use of association rules. It allows companies to understand the relationship between the items bought frequently.
For example, if someone buys product A (say eggs) is also likely to buy product B (say milk and bread) with it.
Understanding how customers consume products can help companies develop better cross-selling strategies and discover correlations within the products.
- Dimensionality Reduction
Dimension reduction is the process in which several features are reduced in a data set. While more features generally produce more accurate results, they can also affect the performance of un-supervised algorithms and make it difficult to visualize data.
This can be done for a few reasons including making the data set easier to visualize, making it less complex, and improving the performance of algorithms.
There are different methods of dimension reduction such as principal component analysis (PVC), singular value decomposition (SVD) autoencoders, etc.
Applications of Un-Supervised Learning
Even though un-supervised learning introduces more risk, it is also well suited for tasks related to large data sets and improves a product user experience. It makes it easier for companies and businesses to gain insights from unlabeled data and identify patterns.
Some real-life applications of un-supervised learning are as follows:
- Fraud Detection: Un-Supervised learning is used to detect and identify data points that are different from their normal behaviour through anomaly detection.
- Image Compression and Text Summarization: Image un-supervised learning uses the method of dimensionality reduction to compress an image or summarize a passage while retaining all the important points in the image or text.
- Customer Segmentation: Un-Supervised learning can be used to group customers based on common traits and similar interests and choices through clustering or association rules. It can help companies to improve their marketing strategy.
- Medical Imaging: Un-Supervised learning is used in a variety of image analyses like segmentation and object identification used in radiology for quick and fast diagnosis of patients.
- Recommendation Systems: items can be recommended to users according to their past preferences with the help of un-supervised learning. Large web platforms like Netflix and Amazon use association ruling algorithms to recommend movies and items to their users.
Advantages and Disadvantages of Un-Supervised Learning
Advantages:
- Un-Supervised learning uses unlabeled data which gives us insight into hidden patterns and structures in large sets of data.
- It is less complex and easier to work with since the data is unlabeled.
- It can handle large-scale data sets and make them more scalable by removing irrelevant features and improving efficiency through dimensionality reduction.
- It has a similarity to human intelligence in a way.
- Un-Supervised learning can detect unusual behavior and anomalies which is helpful in spam detection and fraud detection.
Disadvantages:
- We cannot say that the results made are correct, accurate, or useful.
- Since the data is unlabeled, the clusters or groups made by these algorithms are hard to interpret.
- There is no human guidance so feedback is not possible which can result in irrelevant patterns.
- More time is consumed by the user to interpret data.
Conclusion
Un-Supervised learning is a versatile tool used for large sets of unlabeled data (no correct answer is provided). Despite certain limitations, Un-Supervised learning remains a valuable technique in the machine learning landscape. As data continues to grow exponentially, its ability to unlock the potential within unlabeled data will become increasingly important. By combining Un-Supervised learning with other techniques and human expertise, we can unlock deeper insights and make more informed decisions in various aspects of our lives.
Leave a Reply